What is the return on investing in information architecture?
The following is based on not one, but many true stories …
Once upon a time there was a product director who arrived fresh-faced and ready to tackle a new role in a mid-sized company known for innovation in their category and speed to market. Let’s call this product director AC.
In this new role, AC was managing a team of product managers collectively responsible for not just a single product but a complex ecosystem of products, services and features.
Pretty quickly AC could tell how much more weight was placed on their opinion compared with when they were a product manager who owned a single product.
Everyone had important decisions to run by AC on a regular basis:
- “What should we call this feature?”
- “When should we tell people about this change and how?”
- “Should this call to action be the top priority, or should it be this other call to action?”
- “There are too many things in this navigation, can we remove this one?”
- “How should these two things different teams are building connect for this single customer flow?”
After a few quarters AC got the hang of the role and could dole out opinions like scoops of ice cream – and everyone wanted more. People love direction and AC was a director.
Under AC’s leadership the product grew, and features from the backlog were added at a regular cadence. The marketing team was excited to have so many new things to share with their lists. And the executive team saw product progress that hadn’t happened in years under other product leadership.
Everything felt “by the book” as every product manager had specific measurements by which they were defining individual success, and they were all hash-tag-winning individually.
All the “quick-to-update” arrows were going up, and fast!
But as the quarters wore on AC started to sense something weird. The executive team had growing concerns because longer term brand health metrics were starting to become painful. The employees reporting to AC had a deference to AC’s words that made it hard to know if anyone was being honest.
Worst of all, the pile of opinions and decisions that AC had made along the way with individual teams had added up to somewhat of a mess. What had been done in tiny changes and incremental feature improvement overtime had added up to a loud, everything-is-important, confusing product that was not only hard to use, but also hard to design for, support technically and provide customer support for.
Everything AC’s team worked on was optimized for engagement and speed to market, and nothing was optimized for the long-term good of the business.
As a result …
- Customer service cost had risen dramatically causing a wait time that customers had started to complain about on social media, which in turn raised social media management and PR costs
- Design, tech and research team member retention had declined, and a few scathing reviews from past team members that made hiring difficult and more expensive
- Product managers were starting to feel the effects of constant team churn, with an increase in resignations and of folks taking leave to heal from burnout
- Key customer segments that the business needed to serve in order to be successful had started to refer to the product as “bloated” and “hard to use”
Given the somewhat dramatic turn of events in AC’s life, now seems like a good time to introduce a comparison to some classic Greek mythology.
Meet Narcissus, Echo & Nemesis
When Narcissus was born his mother was told that he would only live a long and happy life should he never discover his true self or reflect on his own existence. So she spent most of her energy enabling her son to never meet his own reflection.
Echo was a wood nymph that fell in love with Narcissus at first sight and followed him around incessantly observing him. Narcissus, constantly sensing company, would plead “Who is there?” to which Echo would reply “Who is there?” because they had been cursed to only be able to speak the last thing spoken.
Eventually Echo was brave enough to reveal themself. But Narcissus rejected and left Echo broken-hearted. Nemesis, the goddess of retribution and fortune, witnessed the heartbreaking incident and decided Narcissus deserved to be punished for his callous behavior.
One day Nemesis led a thirsty Narcissus to a still pool of water knowing he would catch his own reflection while drinking and face his fate. And it worked. Narcissus is said to have had such a strong love reaction to his own reflection that his human existence ended right then and there.
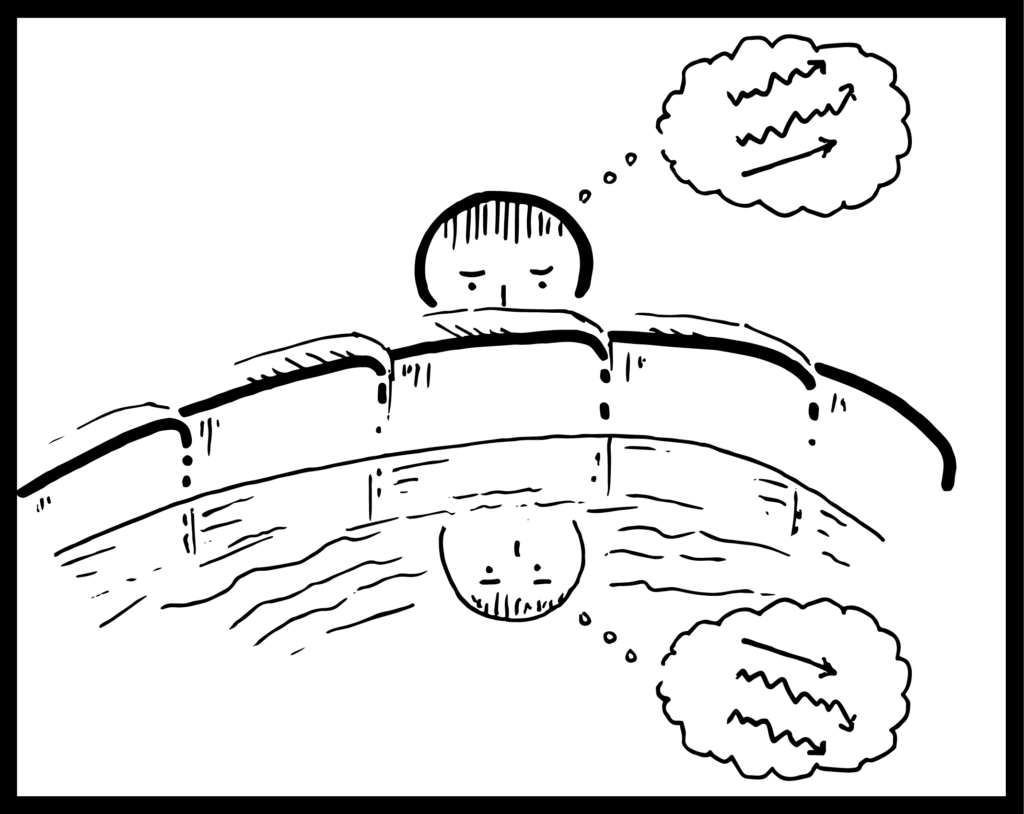
What will AC do in the face of their own reflection?
In the opening story, AC’s reflection is hidden from view. From the start of this new role, AC is not being incentivized to see how their decisions add up to impact the product as a whole (not just the parts).
All those product managers followed AC around offering only echoes of AC’s opinions because they were never being held accountable for any collective value.
AC finally faces their own reflection in those failing long-term product metrics. Unfortunately the executive team also now sees AC’s reflection, and it isn’t good.
At this point, AC is at a crossroads:
- Down one road, AC falls deeply in love with and maybe even becomes defensive of all their past opinions. Maybe becoming even more aggressive with their opinion-based leadership until they more than likely implode their place in the organization.
- Down another road, AC’s self reflection opens their eyes to how powerful a position they are in, and what their opinions add up to in terms of the product as a whole. Down this road, they also see how there is a clear need to invest in the long term health of the shared structures and language of the organization.
If AC chooses to walk down that second road of self reflection and investment into shared structures and languages, thinking deeply about the information architecture of your product or suite of products might be a helpful stop along the way.
I wrote this article as a crash course for a leader who might find themselves in AC’s position as well as for folks who never want to meet that crossroads moment AC is facing.
The below is organized into three sections:
- Elements of a Product Information Architecture
- How to Calculate a ROIA
- Three Mindset Shifts to Start Investing in Your IA
Areas of Information Architecture Investment
Information architecture is the way that we arrange the parts of something to make sense as a whole.
When we are managing a product, we label and arrange the parts within it, and ultimately the way we do that becomes a reflection of the business, and of us as a product owner.
The information architecture of a typical product has six areas of potential IA investment:
- Upper Ontology
- Lower Ontologies
- Metadata Taxonomies
- Navigation Taxonomies
- Controlled Vocabulary
- Business Logic
Upper Ontology
An upper ontology is the model capturing relationships between core entities in a system.
- Entity: A model of an object or player by which many potential instances can exist.
- Instance: A specific object or player that is representative of an entity.
- Relationship: A meaningful connection between entities or instances.
For example: If we were to describe the upper ontology of a two-sided marketplace a diagram of it might look like this. Note: the diagram is NOT the upper ontology, the diagram merely visually represents the upper ontology (which can be hella useful in a number of scenarios!)
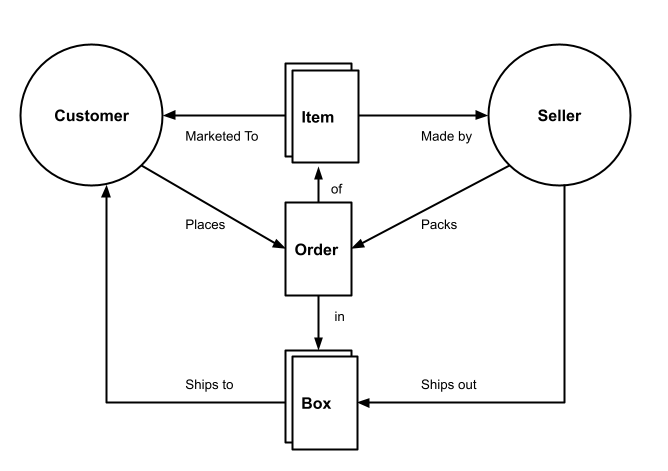
A product’s upper ontology informs everything from interfaces to databases. And it is important to note that these models already exist, even if they have never been diagrammed out.
The key to investing into your upper ontology is acknowledging that it might just be a bit of a chaotic mess at the moment – and that’s ok! (dare I say it is normal, friend)
You can use documentation of your current upper ontology to identify weaknesses that are critical to delivering on lower level goals. This is a critical IA task most products would benefit from investing in.
I was once working on an organization’s upper ontology and amongst a myriad of other issues, they had 12 terms (!!!!!!!!!!!!) for the same 1 entity across their various products. This wasn’t done on purpose, just like in AC’s story – these were all decisions made in pursuit of individual team intentions without understanding the mess that might make when it is all added up.
But there is always a breaking point where the mess finally gets in the way of an organization’s intentions.
In this case, this organization really only faced the reality of their upper ontological mess when they decided to invest in translating and localizing the product suite. Dealing with that ontological nightmare in multiple languages was a bigger mess than making better sense of the English version of the product.
The ROIA here was clear. A flaw in the upper ontology was cascading to produce a costly problem at lower levels of the product. By identifying this problem and creating a plan to change the system overtime to simplify those 12 words we could reduce the cost, time and complexity of the translation task across the product suite.
Lower Ontologies
Metadata is what we know about a piece of content. Lower ontologies are the specific metadata entities, labels, and relationships needed for content to make sense contextually.
For example if you manage a streaming video platform you might need a useful, well-constructed lower ontology for managing the relationship between metadata like Genre, Language, Cast or Series.
These platforms’ ability to meaningfully suggest what you might like to watch next is determined by their ontological approach to their metadata.
For example, liking a certain actor might be machine inferred as potential interest in a whole genre. Or typing keywords and concepts associated with genres or larger franchises will actually return quality results.
It is important sometimes to point out that many of these lower ontologies are created for a specific context within the product, and are therefore unique to that product.
In the below screenshots you can see differences in how genre is approached on Netflix vs. Amazon Prime Video.
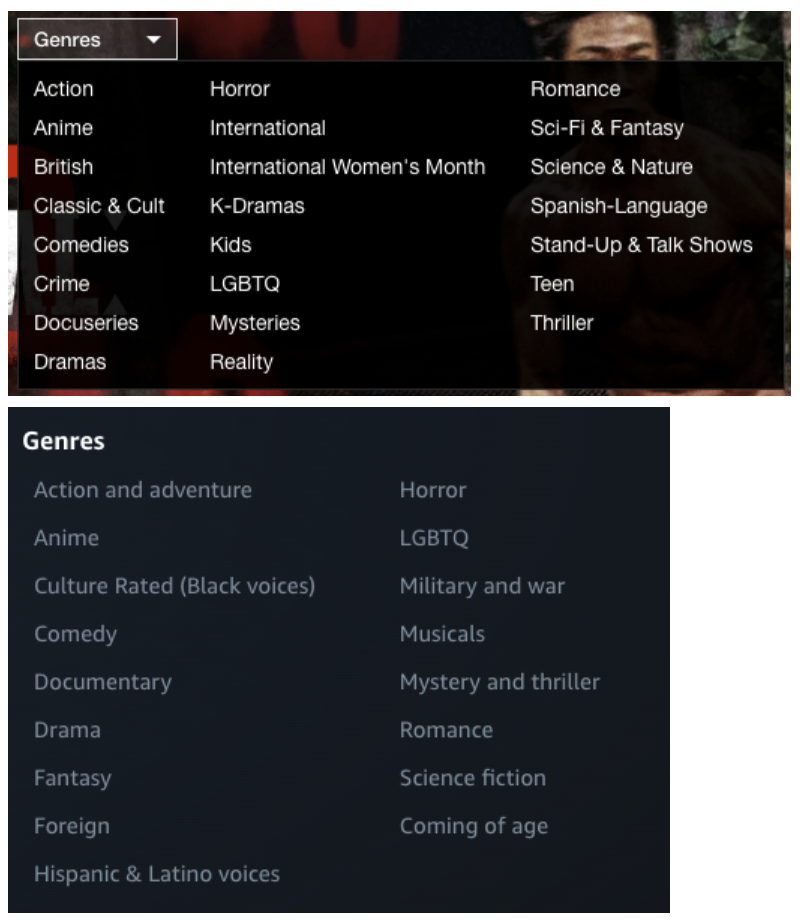
We are not seeing the entirety of what Netflix or Amazon knows about the concept of ‘genre’ in either of these screenshots, we are only seeing what has been prioritized to create a navigation taxonomy.
Each movie or show on each platform has metadata attributes that each studio provides. There is also another set of metadata attributes that the platform likely invests human and/or AI capital into data entry and/or tagging to improve their mappings to their unique ontology.
Lower ontology work is deciding how all that metadata of various provenance relates and should be understood to meet real objectives of the organization.
Resource Alert: If you want to learn more about ontologies (upper and lower), including why you need to think about them in your own product and how to do so check out this excellent article by Bob Kasenchak and Ahren E. Lehnert.
Metadata Taxonomies & Schemas
Metadata taxonomies manage the controlled classification and description of what we know about the content we are using throughout our product. You might also hear people call these metadata schemas.
The content we are describing with metadata might be articles, it might be people, it might be products in an eCommerce catalog, heck … it could be animals in a zoo or art in a museum.
Products are full of metadata taxonomies that determine how to capture, format, store, relate and retrieve metadata about content like:
- Author
- Category
- Features
- Inventory
- Location
- Measurement
- Origin
- Ownership
- Status
- Timeliness
Metadata taxonomies are rarely fully exposed to the user. But don’t be fooled by their shy demeanor, metadata is also the creative powerhouse behind many of the features that people truly value, and that businesses see returns on.
For example, if you wanted to add a simple “You might like …” product suggestion to each item in a large catalog, you would need to determine the metadata on which that inference is best based.
- Is this a new piece of metadata added to every product to support just this feature?
or
- Are multiple pieces of metadata like user preferences, buying patterns, inventory, category and feature all being referenced to more accurately predict what each unique user might uniquely want right now?
Both are jobs where metadata investment is involved. And both involve the definition of a metadata taxonomy that takes into account who adds each piece of metadata, how and when they do so and what the boundaries of their data-entry is to best ensure quality, dependable metadata.
In terms of these two approaches, in my experience
#1 is more likely to:
- Cost way less money and time to deliver in the short term
- Need a manual process for data entry that can become unscalable for catalogs that have a high turnover of their inventory
- Lead to more generic suggestions, and a higher likelihood of users developing ad blindness
#2 is more likely to:
- Deliver higher quality results
- See stronger results for people and better returns for the business in the long term
- Take longer and be more expensive to deliver in the short term
- Introduce a heightened need to pay attention to the ethics of how data inferences can go bad or get too creepy
Unfortunately “Messy Metadata” or “No Metadata” are the two most common reasons I see great creative product ideas stay on the prototype or fail in A/B after doing well in lab settings.
Metadata taxonomies might not be as exciting as a shiny new look and feel or a new redesigned app launch, but nonetheless improving metadata collection and cleanup can do wonders for a product’s health – especially if the content offered is both wide and deep or if search is of heightened importance to users.
Navigation taxonomies are the planned structures through which users can navigate between places or states of a product. Navigation taxonomies specify the labeling, levels of hierarchy and prioritized pathways that users are shown to explain what it is the product offers, and what they can do or expect in certain places within the product.
For example if you manage a web-based product, the navigation taxonomy is the way pages and page states are presented to users in features like filters, hierarchical menus, dropdown menus, breadcrumbs and cross links.
Navigation taxonomies exist in physical space as much as in digital space. For example if you were managing a grocery store, the navigation taxonomy would decide the way the products are divided into aisles and then further into sections.
The below example is one of a set of wireframes I made to illustrate a proposed navigation taxonomy change that reduced Etsy’s top-level category navigation by 50% – going from 600+ links to just 300 in an effort to improve SEO performance (… fyi search performance decline is a common issue with large, bloated navigation taxonomies!)
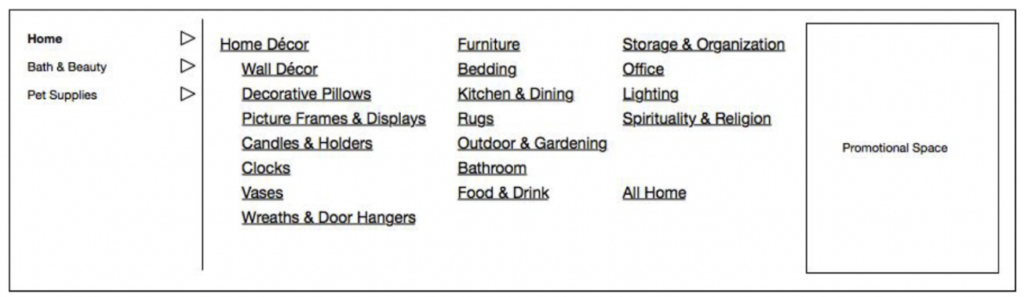
This is an example of the difference between a navigation taxonomy and a metadata taxonomy.
- Etsy has a category metadata taxonomy of thousands of categories and subcategories – in fact they have actually two! One taxonomy is for sellers to classify by, and one is for buyers to find things by. They are mapped to each other so when a seller classifies in the language they understand buyers aren’t hampered by terms sellers might use that aren’t buyer-friendly terms.
- We reduced that to 300 representative links by using a combination of merchandiser partnership, user feedback, search data and category sales analytics to determine the right percentage of the total categories to show in the top level navigation and how to arrange them to make sense to users. Then we worked with the design and technical teams to get it done, and the data analytics folks to set us up to observe our impact.
If you want to read more about this project, Jenny Benevento and I were invited to co-present this navigation taxonomy project at the IA Summit in 2018 and the deck is publicly available.
Controlled Vocabulary
Controlled vocabularies are the documentation of terms and usage of those terms that are acceptable and unacceptable in the context of a product, context and audience.
There are two important potential uses for controlled vocabularies in most product organizations:
- To more clearly communicate to customers outside the organization
- To improve how people communicate inside an organization
In my experience, using diagrams with proposed definitions can create the right dual-coding of words and pictures to get people to react to and take in the definitions and relationships.
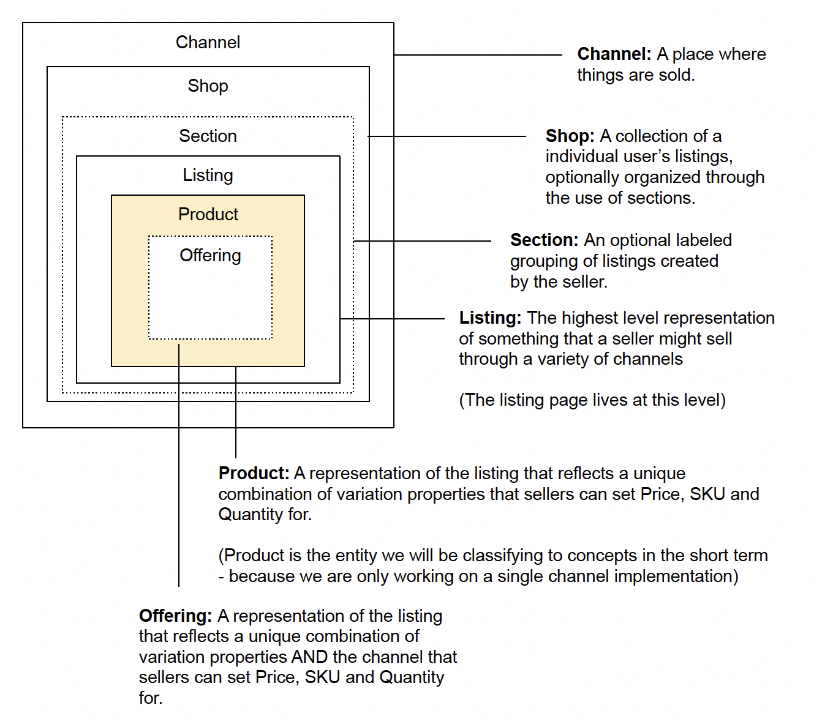
The above is a block diagram I made of a small subset of an upper ontology, notated with definitions of each entity. This document fit on a single slide, but served as a controlled vocabulary for a number of important conversations the team was having as we started to add machine learned inferences into our dataset.
I have made documents meant for controlling vocabularies of hundreds of terms, and many taxonomists and librarians deal with and create controlled vocabularies for thousands of terms. It is important to note that controlled vocabularies don’t have to be exhaustive.
The best uses of them I have seen over the years have been when they are very tactical and meant to address a tangible issue the team is experiencing. One time I put posters on the back of bathroom doors with a list of terms we don’t say anymore and why. Another time I used a gym whistle in large meetings to flag anytime a team member unintentionally voiced a now defunct term.
Resource Alert: If you want to play with a simple structure for controlled vocabularies, check out this controlled vocabulary template from How to Make Sense of Any Mess
Business Logic
Oh my beloved business logic. You are such an unsung hero of most products. Business logic is the rules by which a product presents content and metadata to customize the experience a user is having.
When we make products, especially digital products that are expected to personalize or customize themselves and/or react to the actions of users, we have to consider and document the rules that make that all happen.
Generally business logic is capturing details like:
- Permission levels for different types of users to actions like create, read, edit, undo, and delete
- Acceptable formatting for front and back end metadata and content entry
- Specifications for how content and metadata to be sent/delivered via API
- Error cases users will need guidance and guardrails for
- Security Requirements for features like Single Sign On (SSO) or Password Reset/Retrieval
- Privacy features to assure metadata and content entry and retrieval is not doing potential harm
- Metadata or other circumstances needing a diversion of content flow
- Content or features that change based on factors like audience, context, permission, timeliness
When you list it all out, business logic is a lot of what makes products … well, work! But a pattern I have noticed is how often these types of decisions are made in a meeting or at the last minute when things are being built or even QA-d.
There is no right way to design and build a product, but there is a cost of these important details not being ironed out early on.
I have seen this result in some seriously gnarly instances of a product organization’s worst nightmares:
- Scope Creep: Finding out how expensive and time consuming the business logic is to build or service after interfaces are scoped without an understanding of the logic required.
- Press Blunder: Finding out how biased, offensive, hilarious or harmful your data is by reading about it in the press.
- Algorithmic Cruelty: Finding out truly harmful ways that your lack of data governance has negatively impacted people and knowing it is because you chose to deprioritize humanity in favor of your prediction machine.
- Bad Data: Finding out that the data you have cannot be trusted or used for what you intended because of how it was acquired and/or manipulated.
Messy Metadata: Finding out that you theoretically have the metadata needed, but it isn’t formatted to be easily used to do what you planned with it. Adding an additional cost of data cleaning.
How to Calculate a ROIA
AC’s story illustrates how interwoven information architecture decisions are within a product. But it also hopefully highlights how short-term decision making can create long-term challenges when an information architecture isn’t managed but instead emerges over time, decision-by-decision.
When it comes to making a change to focus on longer term investments, one of the most common questions I get from folks is about how to create the case for a return on investment into IA.
The problem with this valuable and completely expected/legitimate question is that no matter how you spin it, the answer is at a high level too vague for most business-minded people.
“The return on investment on information architecture is whatever you want it to be.“
There is no one right way. There are many ways of reaching your intention, and the way that intention is measured is as varied as intentions themselves. If you want to invest in information architecture to influence people to separate their trash, it would be different than if you wanted to invest in IA to influence people to buy more donuts.
In AC’s story the IA that emerged from their decisions was serving the metrics it was meant to serve. It was the type of metrics that were wrongly over prioritized in relation to metrics that more accurately reflect the health of the overall business. The system was working to plan, it was the plan that was flawed by lack of longer term systems thinking.
The return on investment involved in information architecture work is first in helping teams to define what good actually means in terms of metrics and then figuring out how we will measure progress towards or away from that unique definition of good.
When it comes to products there are some usual suspects for types of measurements we might use an investment into IA to improve:
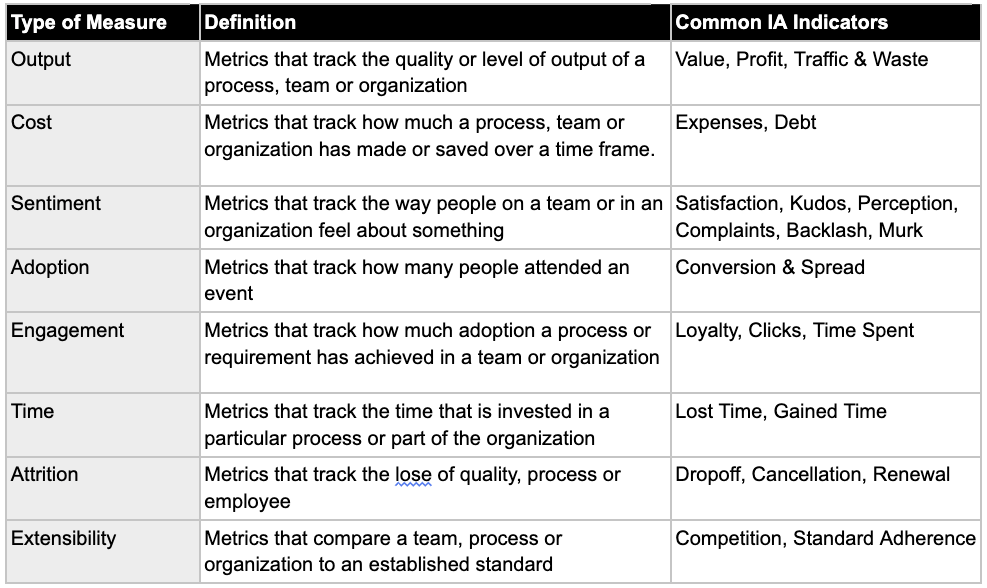
I co-developed the above taxonomy of measurement types with Kristin Skinner and Kamdyn Moore as part of a co-created workshop for the Design Operations Summit in 2019. It was informed by a survey of hundreds of design and operations professionals who were asked about how work is measured in their organization.
For this article I challenged myself to think about the patterns in my experience helping organizations invest in these six areas of their information architecture, to improve these 8 types of measurements.
Below is a matrix showing the measurement types each area of IA investment is most likely to impact. The darker the tone the more likely, the lighter the tone the less likely. It is important to note, it is not my intention to communicate that the lightest toned cells aren’t worth investing in. It just means I haven’t had as much experience attaching that measurement to that type of investment.
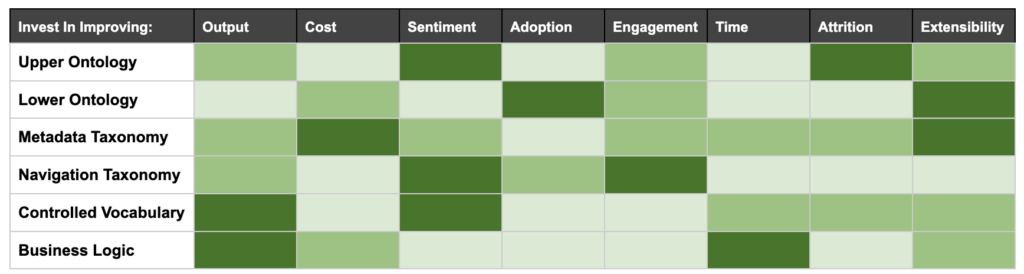
Using the above as your guide, you could …
- Improve your team’s output by investing in your controlled vocabulary and business logic work
- Decrease delivery and/or maintenance costs by investing in your metadata taxonomy
- Improve customer and public sentiment by investing in improving your ontologies, controlled vocabulary and navigation taxonomies
- Increase adoption or conversion by investing in your lower ontologies and navigation taxonomies
- Improve engagement or foster loyalty through focusing on your navigation taxonomy, upper and lower ontology and metadata taxonomy
- Save time by investing in documenting business logic, controlling your vocabulary and collecting clean and useful metadata
- Lower attrition by investing in an upper ontology and metadata taxonomies that make sense to users and stakeholders, even if changing the ones you already have is really hard
- Improve extensibility to technologies like APIs or better compete in the market by investing in your lower ontologies, and metadata taxonomies that will enable features that delight
I hope you can use this matrix to think through a theoretical investment you might make into one of these critical areas of your product. I also hope that if you are currently pushing to improve one of these metrics in the short term, you can use this matrix to guide you on what blindspots you might face in the long term and what the best places to invest in IA today might be.
Three Mindset Shifts Needed to Start Investing in Your IA
There is often a mindset shift required to start investing in information architecture. Over two decades of helping teams with their information architectures, here are three mindset shifts I see most often needed by product owners.
Internalize both “you are not your user” and “your user is not the product owner”
IA is not about taking the results of a card sort and using the most popular frankenstein-folksonomy that was formed by users as the navigation taxonomy. IA is instead about taking those results, and looking at them against the quantitative historical data that you have access to, and the qualitative opinions of stakeholders. The goal is to create what you think is the right structure and language for your product, and then test your proposed structures and language on end users, while preparing to adjust to best meet their needs through the lens of your goals.
Ask “How will we know if …” ALOT
To invest in information architecture you have to understand how and when you will get certain types of measurement data over time about the performance of your product as a result of the changes you are planning to make. The speed, accuracy, importance, visibility and stability of those data streams are essential to understand to make a real impact with your IA investment.
Get ready to ask A LOT of whoever manages your data, if that isn’t you. If you have (::shudder::) never met that person/team, or haven’t talked to them in a while, now is a great time to reach out and check in. If you can openly listen to what they know about your data, they will likely tell you where the data quality pitfalls are currently and where the potential gold is hidden in your information architecture.
Treat language and structure as critical to the success of your product
Things that are critical have accountable leadership. Things that are critical get talked about often and considered thoughtfully. Things that are critical have processes of quality assurance built in to maintain the integrity of those critical parts of the product.
By talking about the language and structure of your product to a wide and diverse audience, and positioning this kind of work as critical to success, you can start to build the respect needed to make real change. If you are a product owner or influencer in a larger organization responsible for only one area of a product, don’t be surprised when your investment and verbalizing of IA work spreads like wildfire to other people and teams. Information architecture is the pain with no name for many teams.
Also if that wildfire catches, it is a great opportunity to offer to lead a cross-product IA investment – which in my experience can be the step up in responsibility that many product managers are looking to take as they move into the next chapter of their leadership career.
—
Thanks for your time. Now, go forth and make some sense of that product of yours.
✍️If you enjoyed my thoughts on this topic you might also enjoy reading some case studies of my information architecture work for Nike, IHOP and Hanna Andersson.
🎥If this article about IA has you interested in learning more, I offer a 30 minute FREE video eCourse called Information Architecture for Everybody covering basic concepts, methods and common questions people ask while learning about IA.
🤓If you are ready to go from curious to confidently practicing information architecture in your own context, consider becoming one of my students by registering for The Practitioner’s Guide to How to Make Sense of Any Mess. This course includes access to my LIVE monthly office hours.
💌If you want to keep up with the latest from me, join my monthly email list. And if you found this to be of value, I would be so appreciative if you sent this piece to anyone else who might also find value in it.